一、首先让我们借用并澄清几个语音学中的概念
1.临界频带与听觉掩蔽
听觉临界频带:设纯音频率为,用噪声(设频率为)掩蔽纯音时,在噪声湮没的纯音的过程中,起作用的是频率在以内的噪声,称为临界频带。即当噪声的频率处于上述区间时,人耳会听不见该纯音,即此频率的噪声对该纯音的听觉造成掩蔽。而频率在区间之外的噪声,人耳可以正常察觉纯音,即不会发生掩蔽。
2.Mel频率尺度
人耳对音调的感知度,不随着频率(Hz)的加倍而加倍,但频率在Mel尺度内,人对音调的主观感知度与声音的频率则为线性关系。MFCC考虑了人耳的听觉特性,且没有任何前提假设[9]。普通频率转换为Mel频率的公式为:
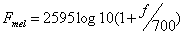
3.滤波器组
将语音信号映射到Mel尺度,并根据人耳所具有的临界频带特性的数学实现,是将每帧语音信号的功率谱,用通过一个如图所示的滤波器组的方法完成的。
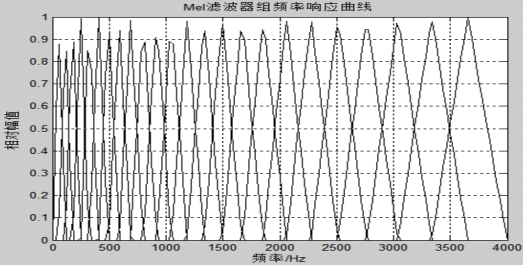
典型的滤波器组是由24个三角形带通滤波器构成的。每个带通滤波器具有的中心频率和频带便是人耳的临界频带和听觉掩蔽特性的反映;且在不同的频率上,每个带通滤波器的带宽是不同的,但在Mel尺度内,则都是等带宽的。
所以,该滤波器组是通过给每帧的语音信号的功率谱加权而模拟人耳的听觉特性的。注意:滤波器组的低频段较密,高频段较稀疏,这个目的是为了提升低频段的能量。
二、特征参数提取的目标
特征参数提取的目标,顾名思义,就应该使相同的语音之间的差别尽可能的小,不同的语音之间的差异尽可能的大。在基于语音的线性模型的下,语音的形成可看做为声门激励与声道的耦合——卷积形成的,即:
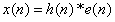
其中,x(n)为语音信号,h(n)为声道,e(n)为激励。
我们的任务是在现有的语音中分离声道和激励,即将卷积运算变换成加法运算。
作FFT后,可得到:
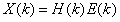
在x(n)的频谱X(k)中,包络的峰值为共振峰,表示语音的主要频率成分,共振峰携带了的声道特性,频谱的细节部分反应了激励源的信息,对上式取对数得:
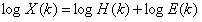
若此处用一个低通滤波器,则可以分离声道与激励。但事实上,声道与激励同是辨识口令的特征。对其再取傅里叶逆变换(IFFT,实际处理时用的是DCT变换,因为DCT的优势在于它对实数进行变换,得到实数,避免了复数运算)得:
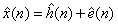
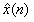 称为x(n)的倒谱,可作为语音的特征参数。以上的方法为同态处理。
称为x(n)的倒谱,可作为语音的特征参数。以上的方法为同态处理。
最后,截取所得的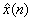 的前12维(一般取12维左右)作为该帧的特征参数,即MFCC,它包含了声门和声道的特性。
的前12维(一般取12维左右)作为该帧的特征参数,即MFCC,它包含了声门和声道的特性。
三、基于MATLAB的实现
function ccc=my_mfcc(x,fs,p)
% x是输入语音序列,Mel滤波器的个数为p,采样频率为fs,frameSize为帧长和FFT点数
%即用统一的数值256,,,,inc为帧移为100,,,;ccc为MFCC参数。
[x1,x2] =my_vad(x); %x为原始语音数据
%frameSize=framelen; %为统一的帧长256
frameSize=256; %frameSize为帧长和FFT点数
inc=100;
% bank=melbankm(p,frameSize,fs);
% % framesize :length of fft
% % 归一化Mel滤波器组系数
% bank=full(bank);
% bank=bank/max(bank(:));
%%-------准备工作-------------
%归一化mel滤波器组系数(24个窗)
bank=melbankm2(p,frameSize,fs,0,0.5,'m');
bank=full(bank);
bank=bank/max(bank(:));
% DCT系数,12*p
for k=1:12
n=0:p-1;
dctcoef(k,:)=cos((2*n+1)*k*pi/(2*p));
end
% 归一化倒谱提升窗口
w = 1 + 6 * sin(pi * [1:12] ./ 12);
w = w/max(w);
% 语音信号分帧
xx=my_enframe(x,frameSize,inc); %需要再次分帧,使用数据
n2= fix(frameSize/2) +1 ; %计算帧长度的一半
xx=xx(x1:x2,:);
% 计算每帧的MFCC参数
for i=1:(x2-x1+1) %x1,x2只是帧的下标 %帧数,循环
y = xx(i,:);
s = y' .* hamming(frameSize);
t = abs(fft(s));
t = t.^2;
c1=dctcoef * log(bank * t(1:n2));
c2 = c1.*w';
m(i,:)=c2'; %每一行代表每一帧,每一帧里有12个数据
end
% ccc=m;
%
%差分系数
dtm = zeros(size(m)); % 帧数*12的矩阵
for i=3:size(m,1)-2
dtm(i,:) = -2*m(i-2,:) - m(i-1,:) + m(i+1,:) + 2*m(i+2,:);
end
dtm = dtm / 3;
%合并MFCC参数和一阶差分MFCC参数
ccc = [m dtm]; %在m的后面再接一个矩阵,共形成了 帧数*24的参数矩阵
%去除首尾两帧,因为这两帧的一阶差分参数为0
ccc = ccc(3:size(m,1)-2,:);
function [x1,x2] =my_vad(x)
% 预加重滤波器
xx=double(x);
xx=filter([1 -0.9375],1,xx);
%幅度归一化到[-1,1]
xx = xx / max(abs(xx));
%常数设置
FrameLen = 256;
FrameInc = 100;
NIS=15; %设置前面无声段的帧数为20,根据自己所采集的样本,一般有0.5s的无声段,<30*200/16K=0.4s,可行
amp1 = 6;
% amp2 = 0.3;
amp2 = 0.15;
%zcr1 = 10;
zcr1 = 1;
maxsilence =60; % 30*10ms = 300ms,最大静默时长,即,未超过maxsilence的长度,仍然为有声段
minlen = 30; % 15*10ms = 150ms ,用来检测排查噪声的
status = 0;
count = 0;
silence = 0;
amp=my_STEn(xx,FrameLen,FrameInc);
zcr=my_STZcr(xx,FrameLen,FrameInc);
ampth=mean(amp(1:NIS)); % 计算初始无话段区间能量和过零率的平均值
zcrth=mean(zcr(1:NIS));
ampth_v=zeros(1,length(zcr));
for i=1:length(zcr)
ampth_v(i)=ampth;
end
zcrth_v=zeros(1,length(zcr));
for j=1:length(zcr)
zcrth_v(j)=zcrth;
end
m_amp=abs(amp-ampth_v);
m_zcr=abs(zcr-zcrth_v); % 每帧的能量和过零率都减去前面都是噪声段的相应的数值
%计算过零率
% tmp1 = enframe(x(1:end-1), FrameLen, FrameInc);
% tmp2 = enframe(x(2:end) , FrameLen, FrameInc);
% signs = (tmp1.*tmp2)<0;
% diffs = (tmp1 -tmp2)>0.02;
% zcr = sum(signs.*diffs, 2);
%计算短时能量
%amp = sum(abs(enframe(filter([1 -0.9375], 1, x), FrameLen, FrameInc)), 2);
%调整能量门限
amp1 = min(amp1, max(m_amp)/5); %高门限
amp2 = min(amp2, max(m_amp)/15); %低门限
zcr2 = min(zcr1, max(m_zcr)/5);
%开始端点检测
x1 = 0;
x2 = 0;
for n=1:length(zcr) %帧数循环
% goto = 0;
switch status
case {0,1} % 0 = 静音, 1 = 可能开始
if amp(n) > amp1 % 确信进入语音段
% if amp(n) > amp1 | ... % 确信进入语音段
% zcr(n) > zcr2
x1 = max(n-count-1,1);
status = 2;
silence = 0;
count = count + 1;
elseif amp(n) > amp2 | ... % 可能处于语音段
zcr(n) > zcr2
status = 1;
count = count + 1;
else % 静音状态
status = 0;
count = 0;
end
case 2, % 2 = 语音段
if amp(n) > amp2 | ... % 保持在语音段
zcr(n) > zcr2
count = count + 1;
else % 语音将结束
silence = silence+1;
if silence < maxsilence % 静音还不够长,尚未结束
count = count + 1;
elseif count < minlen % 语音长度太短,认为是噪声
status = 0;
silence = 0;
count = 0;
else % 语音结束
status = 3;
end
end
case 3,
break;
end
end
count =count-silence/1.2; %根据经验设定的长度,silence/3也可以
x2 = x1+count-1; %x1,x2为语音的起止帧号
% inc=FrameInc;
function frameout=my_enframe(x,win,inc)
nx=length(x(:)); % 取数据长度
nwin=length(win); % 取窗长
if (nwin == 1) % 判断窗长是否为1,若为1,即表示没有设窗函数
len = win; % 是,帧长=win
else
len = nwin; % 否,帧长=窗长
end
if (nargin < 3) % 如果只有两个参数,设帧inc=帧长
inc = len;
end
nf = fix((nx-len+inc)/inc); % 计算帧数
frameout=zeros(nf,len); % 初始化
indf= inc*(0:(nf-1)).'; % 设置每帧在x中的位移量位置
inds = (1:len); % 每帧数据对应1:len
frameout(:) = x(indf(:,ones(1,len))+inds(ones(nf,1),:)); % 对数据分帧
if (nwin > 1) % 若参数中包括窗函数,把每帧乘以窗函数
w = win(:)'; % 把win转成行数据
frameout = frameout .* w(ones(nf,1),:); % 乘窗函数
end
%短时能量计算函数
function para=my_STEn(x,win,inc)
X=my_enframe(x,win,inc)'; % 分帧
fn=size(X,2); % 求出帧数
for i=1 : fn
u=X(:,i); % 取出一帧
u2=u.*u; % 求出能量
para(i)=sum(u2); % 对一帧累加求和
end
end
%短时能量计算函数
function para=my_STEn(x,win,inc)
X=my_enframe(x,win,inc)'; % 分帧
fn=size(X,2); % 求出帧数
for i=1 : fn
u=X(:,i); % 取出一帧
u2=u.*u; % 求出能量
para(i)=sum(u2); % 对一帧累加求和
end
end
%短时过零率计算函数
function zcr=my_STZcr(x,win,inc)
X=my_enframe(x,win,inc)'; % 分帧
fn=size(X,2); % 求出帧数
if length(win)==1
wlen=win; % 求出帧长
else
wlen=length(win);
end
zcr=zeros(1,fn); % 初始化
delta=0.01; % 设置一个很小的阈值
for i=1:fn
z=X(:,i); % 取得一帧数据
for k=1 : wlen % 中心截幅处理
if z(k)>=delta
ym(k)=z(k)-delta;
elseif z(k)<-delta
ym(k)=z(k)+delta;
else
ym(k)=0;
end
end
zcr(i)=sum(ym(1:end-1).*ym(2:end)<0); % 取得处理后的一帧数据寻找过零率
end
